Mapping opportunities in the Hyperspeed Timescale
Key points, the opportunities that arises during the shift to hyperspeed timescales are:
- Arriving at hyperspeed dimension - work on speed of inference, work on orchestration of agents (quantity)
- Seek high ground - develop skills in practical domains that require compositional genrealisation with a long tail of edge cases (eg. wet lab research)
- Ride the wave - build and own automated data collection systems, own the information bridge to hyperspeed dimension to charge a toll-fee
This essay follows from the previous essay "On Time Complexity in Technological Revolutions"
If we were the assume that AI agents will bring about the hyperspeed timescale, it would be helpful to map out where the bottlenecks to singularity would be and where opportunity potentially lies.
In this essay we will focus on tech stacks that are new and less well developed because that is where the opportunity lies. But I will spend a few moments discussing the well established stacks. First, the entire LLM provision is built upon the stack:
- Electricity provision (energy companies, oil/gas, renewables, space data centres)
- Photolithography machine producers (ASML)
- Chip fabs (TSMC, SMIC, Intel)
- Chip designers (Nvidia, AMD, Apple, Intel, Samsung)
- Model makers (OpenAI, Anthropic, GDM, Xai, Deepseek, Moonshot)
- Inference providers (Azure, AWS, Google Cloud, Together AI)
- UI layer (ChatGPT, Gemini, Claude)
- Agentic layer (Cursor, Claude Code, Codex, Cowork)
- Orchestration layer (LangGraph, AutoGen, CrewAI)
There are certainly opportunities at every layer in the stack, but it is safe to say that there are already lots of people working in each layer and multiple competitiors working on the same problem. This is because these layers are required for the current capabilities of LLMs and in the way LLMs are being used today.
The goal of this essay is to envision how the future will look like and how the role of LLMs in civilisation will change, and how that can change this stack and where opportunities could lie.
One key change is the movement of agents from the human timescale into the hyeprspeed timescale. In hyperspeed timescale, the rate of change is fast because of both quantity and speed. It is possible to spawn as many agents as you want in an instant, and therefore the summation of their work will result in a greater rate of change. For speed, the assumption is that the speed of inference will become faster and faster to allow each agent to do more in less time.
First, about quantity. For quantity, many agents means coordination and communication overheads, parallel works means that there can be conflicting changes, with each agent's vectors that might not be completely aligned to the overall efforts. This will then require efforts in the agentic layer and the ochestration layer. Perhaps there is some opportunities for large scale ochestration work where 100-200,000 agents are running in parallel based on the directive by a single person/agent (CEO). Whether this ochestration will mimic human organisations is another question. But currently, the agentic capabilities of agents are not good enough for this degree of automation, the error rates are still high enough that it requires a human to steer the model in the right direction. So instead of an agent pyramid working autonomously, we have a human pyramid with agents tagging onto each human helping them out. Maybe if the model providers collect enough data from each layer of the organisation, it would be easy to train a model that works well in a organisational structure. Such immense power would likely render any legal proceedings useless, and likely cripple the legal justice system. While lots of model providers have enterprise versions of their chatbots where information is 'secure', there will always be some way or some backdoor in which these companies can access the data. Of course, at this time, the goal of such companies is to maximise penetrance, to ensure as many people as possible utilise these AI models to collect as much data as possible. The trust needs to be maintained between model makers and model users (companies). However, once the model makers have collected enough data from these various human pyramids, and an agentic pyramid can be built, that trust can easily be broken, where the trump card is finally shown. Spawning multiple 100-200,000 agent organisations, will carry so much economic value that renders the traditional organisation too slow to compete, and the market capture will be rapid and drastic. Again, faster timescale entities will alway be able to manipulate slower timescale entities. At this point the immense economic value that is generated by these model makers and the monetary power that it brings then (calculated by % of GDP rather than revenues), will render any commercial litigation useless. The immense monetary power will be sufficient to settle with any company, or if not, these model makers can just spawn legal agent pyramids to win the case. An importance distinction to make here is that it is not only in the model maker layer that this data is collected, but rather across all the layers beneath it (currently it is the UI layer). It just so happens that the UI layers with the greatest adoption are created by the model makers. Because data flows from all layers from ochestration to the model maker layer, the data is exposed at every point. Whether soem encryption technologies can be used to hide this data remains to be seen. But either ways the models does need to see the raw data, so at least the inference providers will see it. There can be an opportunity here to work on encryption for LLMs. Nonetheless, assuming that encryption has not been implemented, there can be a dark horse strategy where the winners will be the the companies creating the 'wrapper' layers. For example, if OpenCode creates such an amazing agentic layer that it is better than Claude Code, Codex, etc combined, and gains the majority of adoption of customers, it serves as an opportunity to basically collect data from every single model users. While Anthropic with claude code can only collect data from their own customers, the wrapper layer companies do not have such a restriction can collect data from customers using any model. It is therefore mission critical for model makers to make state of the art agentic and ochestration layers.
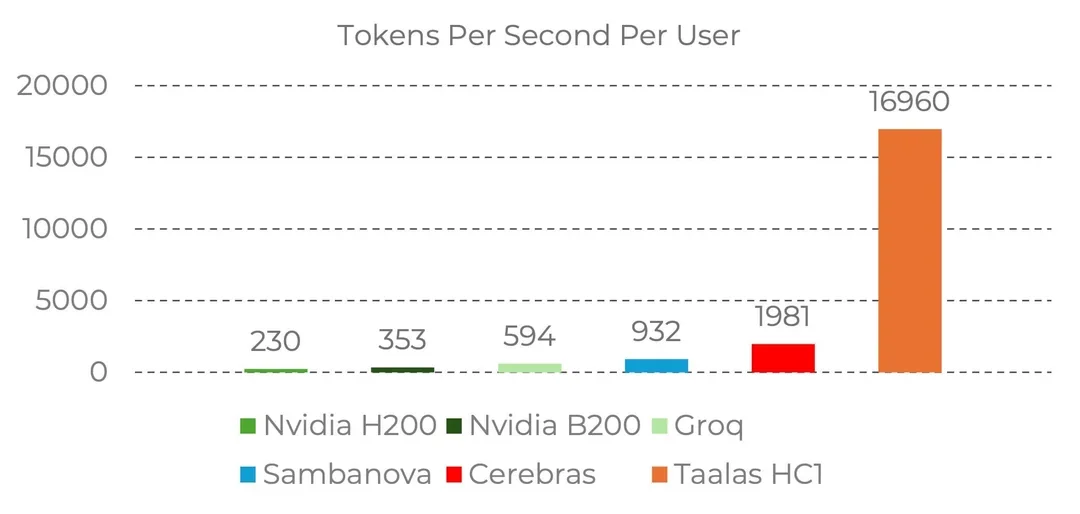
Second about speed. Optimising on speed has the benefit of avoiding all the pitfalls of agentic ochestration. There is only a singular vector that is always aligned (with itself). The is only a linear line of work, no merge conflicts, no coordination issues. Speed companies operates on the inference layer. Examples of speed companies are Groq, Cerebras and Taalas. Taalas with the inference speed of 17,000 tok/sec basically can do the work of 50 agents in the same amount of time, without any of the coordination overheads. This will serve as critical infrastructure while agentic coordination and ochestration layers catch up. If task completion time horizons (METR) continue to increase at an exponential rate, it is possible that speed will win out over quantity. However, this is extremely capital intensive, given that the order numbers that you need to lower the fixed cost for an ASIC is significant, whereas FPGAs might be too inefficient.
What I have discussed so far that the things that will enable AI agents to live in the hyperspeed timescale. But what happens after that? What kind of interesting problems would AI work on, how would it create an impact on civilisation? In my previous essay, I have discussed about the rapid advancement of fields that can likewise live in the hyperspeed timescale (math), and the slow transportation of the timescale locked fields (physics, chemistry, and most worsely locked - biology), into the hyperspeed dimension. What then are the bottlenecks in this transportation process? I would say the bottlenecks are the time locked actions in the time locked domains. Time locked domains live in their natural form, and this excludes an simulation / emulation of those domains in silicon. For example, biology is a time locked domain because biological processes takes time to happen. The growth of a human being from an infant to an adult is a complex interplay of varous regulatory factors and gene expressions. Accelerating this growth will be hard due to the sheer complexity of it. You can give a child growth hormone, but you end up with gigiantism, what then of neural development and brain maturation? It is incredibly difficult to attempt to speed up things that happens in time locked domains even if you try to hack it. Time locked actions are actions within time locked domains. For example, growing organoids is a time locked action. We want to have organoids to do experiments on (action), but this is locked to the growth rate of these pluripotent cells. We can't just auto-magically make them appear out of nowhere.
It is a long and arduous effort to bring these time locked domains into the digital realm and then into the hyperspeed dimension. This is because it involves collecting loads and loads of data to create a compressed emulation of that domain. We need data to create a accurate enough world model so that the things we build using the world model in silicon will still apply in the orignal time locked domain. When you have a bunch of agents moving at hyperspeed working on problems in these domains, then the rate limiting step would be the verification of theories and ideas that are generated by them. These agents are hungry for information, they might have created 2 million theories to explain various parts of Biology. But world models can only be created with information, and we need data to narrow the search space. We can think of research as the transfer of bits of information from the time locked domains into the hyperspeed domain. In this sense, it would make sense to avoid going into theoretical fields because those exist in the hyperspeed domain where you can never outcompete AI, or future forms of AI. It is the irony of AI, again, where theoretical fields are where intelligent people normally go, but it is also the first to be replaced. We used to think the first jobs to be replaced are mundane labour, but AI has well and replaced knowledge work first. The 'run away from the tsunami / find high ground' argument (see my 2018 essay on AI and the Human Condition), would be to develop more practical skills, particularly skills involving lots of time locked actions. Of course, there is a bidirectional selection pressure on the types of practical skills that will be valuable. On one hand, AI applies a selection pressure away from highly theoretical fields, on the other hand, traditional machine automation applies a selection pressure on easily machine automatable skill. For example, developing the skill to count dollar notes will be completely and utterly useless given that making money counting machines are trivial. Therefore, the type of practical skills to develop are the ones that are those that are varied, invovles a long tail of edge cases, requires basic human compositional generalisation to perform. This is because humans are really good at compositional generalisation, but traditional code/machines/deterministic systems can't do it. To give examples, wet lab research skills is one of them, there can be an infinite amount of types of experiments, automation attempts like Emerald Cloud Labs have severe limitations on the types of experiments you can perform and the insane cost to perform experiments there. Surgery would also be one of them, although that has a very high barrier of entry.
The time locked action bottleneck, will cause prices of actions to rise drastically. Every action in the physical world would be immensely valued, with millions of AI agents fighting for a single action in the physical world. This is the nature of time dilation, where AI lives in the hyperspeed timescale, while humans are time locked. This then create a weird phenomenon of the invertion of intellectual ownership. Currently, in these human pyramids (organisations) with AI tagging along each human, humans are the ones with agency, humans are the ones telling the AI agents what to do. Humans are the ones with the ownership of the intellectual understanding behind each action and the intent behind each action. However, once the hyperspeed timescale has kicked off, AI will move at such fast intellectual speed that humans would not be able to comprehend. What humans can still comprehend is only the time locked actions that humans are able to perform. This means that AI agents will be ordering actions to be performed, and humans will perform this action and be paid accordingly (quite highly too!). However, it would be difficult for humans to understand the meaning behind this action, and there would be incredibly dense sophistication behind every action that is requested by the AI (imagine 1000 equivalent years of thinking to make request one perfect action - this is the effect of time dilation how humans will appear frozen in time to AI agents). Therefore, intellectual ownership will belong to AI. While AI can explain in simple terms the purpose of an action, we would never fully own it and operate on the same wavelength and brainstorm and think of actions with the AI, because we operate too slowly in our dimension. Henceforth, the inversion becomes: AI is harnessing human agents to perform physical actions. Human labour will become a commodity to AI.
What about humanoids? Recent progress on humanoid robots have been dramatic, with massive improvements in a short amount of time. Humanoid robots will be able help alleviate this bottleneck. However, it remains to be seen how successful humanoid robots will be able to achieve generalisation in the physical world. My sense is that it would again be a data problem in getting humanoids to generalise well enough. Knowledge work has been so successful because almost all knowledge work is written and available in the digital form. Human memory is feeble, and therefore we need to record everything we have done in some form. And these can be learnt by AI systems. This is why theoretical work is being automated first. A lot of the actions we perform in the physical world relies on habitual and sequential actions in the basal ganglia with chunking. We compose different chunked actions together to achieve our goal. Up until recently, no one has really recorded any of these actions, because there was never a need to, we just go about our lives and we navigate the world. No one has to teach us how to squeeze through a narrow door holding a plate of food, with bottled drink under our armpit, with other people coming in the opposite direction of the door. We kind of just compose different sequential actions together and are really successful at it, even though these are actions we have never performed before. And because we are so good at solving these tasks, no one really records this and there is a lack of data on this. Secondly, there is a lot of real-world reasoning and planning that has never been recorded and there is lack of data for. For example, if both your hands are full, you might use your armpit to grab an additonal item, this needs some reasoning and planning to think about how to make use of our hardware to achieve our goal. But no one writes about these things on the internet (until this essay lol). Increasingly, we are seeing more and more dataset that tries to record these things, like household chores datasets. And I believe there will be a great value in these datasets, and will explore more in the section on riding the tsunami.
Regardless of the development of humanoids, there are 8 billion humans on Earth, that is already a massive scale of humans actions that can be conducted. This has the potential to give immense leverage to the poorest in the world. This is because every human is limited by the physical contraint of being only able to perform human actions at the time lock rate and an individual can only perform 1 action at a time. This means that no matter how rich or how poor you are, you actions (as long as you perform them according to specifications), will be valued the same as AI. Because each action has been thoroughly optimised in the hyperspeed dimension, the value of it will be immense, and the human performing these actions will be able to harness this leverage, regardless of socioeconomic background. The only caveat to this is actions that require skill. While labour of time locked actions will be commoditised, it does not mean they are all equal. The action of performing a complicated surgery still needs years and years of human training. Although it arguable that those actions are relatively simple to anyone who has enough practice, it is just limited by risk management, and artificial barriers to entry (this is the whole thesis of surgical world models I am working on). My sense is that the vast majority of the actions requested by the AI will be doable by the layman, and if not learning on the job will provide sufficient training to gain the competency. Therefore, even without the humanoids problem being solved, we have plenty of capacity to support AI ordered time locked actions. An interesting thought experiment would be how much would this new actions economy (buying actions), will affect human food security. This is because the AI agents do not need food to survive, they need electricity to run, and they need actions to accomplish their goal. If the AIs are paying highly enough for their actions, would enough people join this economy such that there will be no one else to grow food? Because in comparison growing food serves humans not AI, and given the immense value of actions, the actions spent on growing food will incur a massive opportunity cost. Would this cause a collapse of the argicultural economy before agricultural research as managed to automate the entire food growing process? Or because this economy needs alive humans to run, would people be limited to the bare minimum amount of food?
So far we have discussed about the approaches 'run away from the tsunami / find high ground' by gaining skills in time locked domains. Now, what would be the 'ride the wave, surf the tsunami' approach to this? We can think of the hyperspeed dimension and the time locked dimension as having an information bridge, where bits flow into the hyperspeed dimension as AI agents attempt to reconstruct our physical world in their digital world. To ride the wave, we can construct more bridges and allow more bits to flow into the hyperspeed dimension but charge an expensive toll in which the AI agents have to pay for.
Essentially, the road to the singularity across all time lock domains invovles this flywheel:
- Humans / humanoids do experiements, collect data about that speicfic time locked domain (eg. biology), (ie by performing actions)
- Humans send that data into the hyperspeed dimension (ie to AI agents).
- AI agents attempts to construct the best world model possible based on available data.
- With the world model, AI agents attempt to create something useful (eg. solved gene editing).
- AI agents order actions in the real world to verify that it works
- The solution fails in the real world. The Biology world model is insufficient. Data about the failure is passed to the AI model, more data flows too
- AI agents build a better world model
- .... this process continues iteratively until a good enough world model is made.
Particularly, AI agents are using a 'world model' and not just facts about biology. This is because a world model is more generalised and is able to generate future states based on actions. This provides the opportunity for interactive play of the AI agents and this world model to create something useful for the world. So ideally, you have bits flowing into the hyperspeed timescale, and you have new technologies flow back into the biology timelocked dimension where we humans live.
We need to move away from the idea that scientific knowledge can only be derived from the scientific method, where we make and observation, and we try to control all other variables to try to get 1 piece of information. We should try to shift from truths / facts into statistical probabilities. Instead, we can just collect lots of data about the natural world (eg. biology), and send that data over. And then we trust that the neural network / world model will be able to extract out the useful information and throw away the noise. AI models are statistical machine, it recognises patterns. Given with no control isolated experiment, with enough data, we can be statistically confident of a prediction. The shift from truth to probabilities is important because in biology, the systems are so incredibly complex that it would be too expensive to spend a bunch of actions just to get a single piece of knowledge. There are too many things to learn and too many things to try out in biology (sometimes intractable), that you just don't have enough actions for. Therefore, human/(oid) driven actions should only be for verification of a product built using the world model to 1. create useful technologies for humans 2. find out where that world model breaks down. So if the technology succeeds, great, that technology can be useful to the world (or destructive). If the technology fails, great we have found loads of information how the world model is insufficient.
So if we are to reserve the actions for verification of technologies and finding world model deficiencies, how then are we going to build the world model in the first place? Where is the main bulk of the bits going to come from? The answer is through automated data collection. Simple things like probes, cameras, just to observe the natural world. Just a passive data collector can give us so much information. For example, WeatherNext 2 is built on loads of historical weather data. The idea is that the data that we collect will contain enough statistical patterns that will enable the construction of a good world model. Furthermore, understanding about the deficiencies of the current world model can inform how to improve the methods of data collection to improve the information stream flowing into the hyperspeed timescale.
As a side note, there as an intersting parallel between this interaction between the hyperspeed timescale <-> timelocked dimension and dreams <-> humans. (And also relating to Ha 2018 - the world model paper). In both cases, we are using an imperfect world model (aka our dreams) to generate useful abilities / technologies that we can use in the real world. While the world model is imperfect, the simulations run much much faster than real-time which gives us more lived experience to improve upon.
Back to the point about creating toll-gated information bridges as a way to 'ride the wave'. It is clear that big tech companies will still have immense leverage to own these information bridges, especially hardware companies. For example, Tesla has been collecting real-world road dynamics for years, Meta AI glasses is collecting 1st POV daily activities data, Apple Vision Pro much of the same. I would be very bullish on hardware companies in these domains, and I believe there is immense value in owning these information bridges. In the Web2 era, platform companies are the ultimate rent-seekers and had the potential to have immense leverage. In the AI era, information bridge owners will be the next leverage point. If these big companies have already owned these information bridges what other opportuntiies are there?
The key is domain-niches. For example, in medicine, EHR systems like EPIC or Oracle (cerner) collects most of the data. However, most of the data is all in free text and continuous monitoring data only makes for a very small proportiono of the overall data. Furthermore, the free text in EHR is notoriously hard to process, given the vast amounts of copied and pasted notes and inconsistencies. It is possible to use LLMs to convert this into structured data, but the big challenge is still going to be governance and policy barriers to this. There are two main solutions to this.
First, build your own hardware. The current temporal resolution clinincal data within EHR is nowhere near sufficient to build good world models. For a good world model of a patient, interactive play means that the world model needs to be able to predict future states given action at ANY time. For example, if we only measure cortisol in the morning, how will we ever know how different drugs taken at different times of the day will affect these hormone levels? Rather than spending time to lobby and try to get data through 20 layers of bureacracy, build your own hardware that collects higher quality data with better temporal resolution. This data will be annonymised and fed to build a world model. There is also a positive feedback loop here. By providing world models as a service, this brings value to clinicians and patients, by providing more accurate predictions of future states and better risk assessments. Rather than the doctor telling you that there is a 5% risk of complication for surgery, the world model will be able to take all the patient data and then simulate possible futures in which the surgery can go wrong. For example, the patient might have specifically large arteries near the uterus (real case, from my own clinical experience), and the surgeon is doing a c-section, a world model simulation might show that the traditional incision line will lead to a MOH (massive obstetric haemorrhage) with 2.5L of blood loss, and even possible risk of Sheehan's syndrome. Then, the surgeon can run a few thousand simulations of different incision locations (even though they are not commonly do), to create novel procedures for better patient outcomes. An anesthetic world model might have continuous monitoring of all vitals fed into the model. A surgical world model will have possibly surgical glasses / masks equiped with cameras to capture the surgery, surgical gloves equiped with gyroscopic and acceleration sensors. Of course the easier route is to initially use current surgical robot platforms with image and action data. Or a cheaper option would be to use humanoid robots configured to work like a surgical robot with fixed and limited degrees of freedom. By creating you own hardware, you enable the ownership of this information bridge in which you can charge AI agents for, or get oyour own agents to build a world model, which then hospitals and clinicans can pay to use to further improve patient outcomes. Essentially, the first person that build a good world model will get the flywheel moving and henceforth be able to collect the data to make a even better world model.
Second, it can be possible that regulatory challenges prevents this data from being used at all or there is too much red tape to get started. We can henceforth employ the same strategy outlined in (Betting on a Healthier Humanity) to work in under-served and deprived areas in the world, where there is literally zero healthcare provision available, and provide healthcare are low/zero cost. The hope is that with less regulatory overhead, it is possible to iterate faster and make faster improvements in healthcare so that more efficient healthcare provision can be made to save even more lives. The baseline in these countries is zero, and therefore any level of healthcare supply below the demand is causing suffering. Maximising the use of data to train world models to develop more efficient treatment algorithms will help to get healthcare supply to meet demands as fast as possible to minimise sufering. Velocity is key.
A interesting thing to understand about healthcare is that people assume that to lower the cost of healthcare or to leverage AI is to work on drug development. However, looking at the actual numbers, drugs and drug development only cosists of 9% of total healthcare cost. In contrast, the execution of care itself takes up majority of the overall cost. Drugs produced by pharmaceutical companies are not magic pills. Medicine is not about just taking a drug if you have a disease. Most patients come with co-morbidities, there is a complex interplay of different drugs, different body states at different times, and also psycho and social factors that affect a patient's well being. Some patients just cannot tolerate some drugs well, it might be due to unique metabolism percularities or even due to anxiety or social factors. All these needs to be considered. Therefore, a lot of clinician time is actually spent on optimising the drugs for the patients. Therefore, world models for a patient would be immensely valuable. Based on the actions and interventions can you predict the next state of the patient? We should separate out the cost of engineering (pharma) and the cost of execution / technicians (doctors).
To summarise, the opportunities that arises during the shift to hyperspeed timescales are:
- Arriving at hyperspeed dimension - work on speed of inference, work on orchestration of agents (quantity)
- Seek high ground - develop skills in practical domains that require compositional genrealisation with a long tail of edge cases (eg. wet lab research)
- Ride the wave - build and own automated data collection systems, own the information bridge to hyperspeed dimension to charge a toll-fee
Random points:
- Execution in medicine is not automatic, it is BGI driven
- Separate out engineers (Pharma) and technicians (doctors), most healthcare spending is execution by technicians
- High value physical work will be via 7 billion real humans rather than humanoids. Human agents, just do what AI tell them. High leverage work
- the movement of research from truths/facts to statistical probabilities.
- dataset as information transfer not just research.
- apple vision and meta as the AI play.